
La firme de Mountain View projette de convertir en HTML, les documents PDF afin de pouvoir mieux les indéxer dans son moteur de recherche.
Google souhaite optimiser l’indéxation des documents de type PDF, Word ou Excel en les convertissant en « HyperText Markup » (HTML). Pour information, l’algorithme indexait déjà ces formats dans les résultats de recherche. Mais sans balisage « Hn » (H1, H2…) ils sont plus difficile à interpréter par le moteur de recherche tout comme pour l’optimisation en référencement.
Voici une capture de résultats PDF et .PPT dans la SERP :
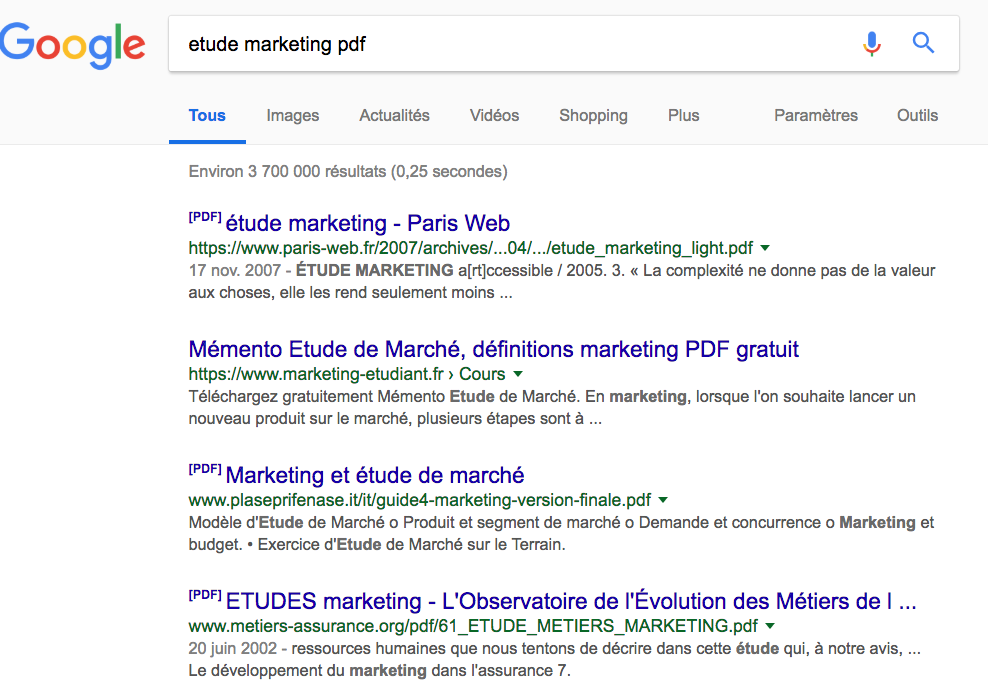
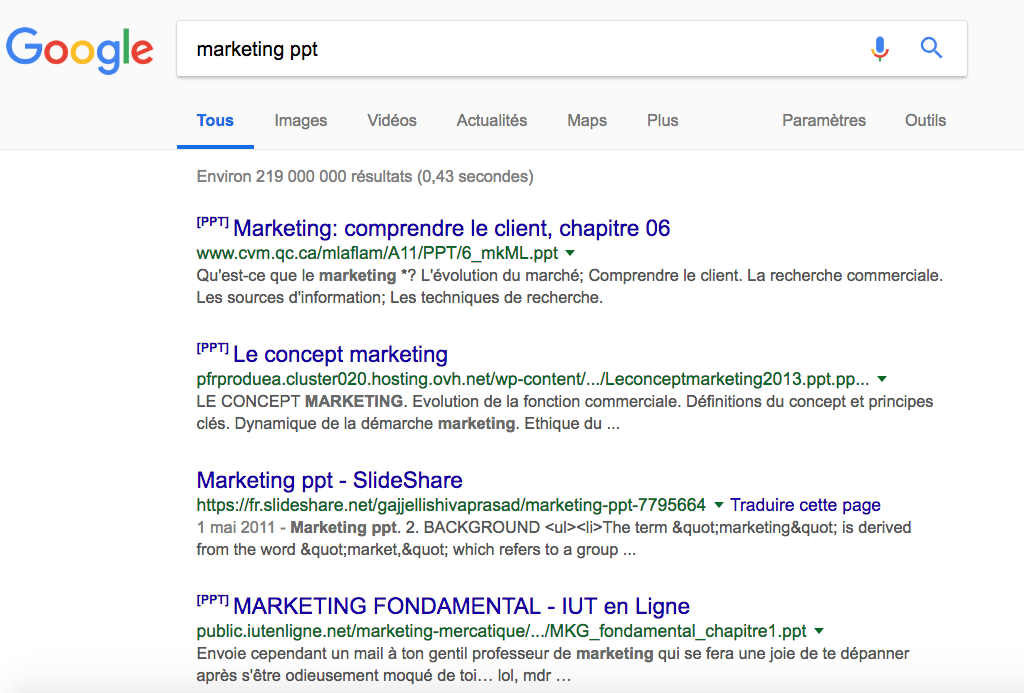
voici ce que dit Google sur la mise à jour:
La technique est de formater le PDF avec des schema qui incluent des balises, pour faciliter au maximum sa compréhension par l’algorithme.
D’autres points sont aussi important prendre compte lorsqu’on parle du référencement de ce type de fichiers comme le duplicate content. En effet, Google conseille de faire attention si jamais votre contenu existe dans les deux formats.
Notez aussi qu’en général, lorsqu’un internaute tombe sur un résultat de recherche PDF, il aura tendance à seulement le télécharger sans forcément visiter les autres pages du site qui l’héberge. Un manque à gagner incontestable pour les éditeurs web.
Réfléchissez donc si vous souhaitez vraiment indéxer ces fichiers ou plutôt traduire le contenu en format HTML afin qu’il profite aussi à votre stratégie de référencement.
Si vous le souhaitez, il est possible de bloquer l’indéxation des fichiers PDF en ajoutant des lignes dans le fichier « .htaccess » de votre serveur.
#Bloquer l’indexation des fichiers Word et PDF
<files ~ « \.(doc|docx|pdf)$ »>
Header set X-Robots-Tag « noindex, nofollow »
</Files>
Dans tous les cas, pensez maintenant à ajouter des schema et des markups pour aider Google à interpréter vos fichiers PDF. D’ailleurs l’outil d’analyse de
Que pensez-vous de cette mise à jour ?