

Le contenu dupliqué (duplicate content en anglais) a longtemps soulevé des questions pour les experts SEO. Est-ce une bête noire à absolument éviter sous peine de pénalités ou de désindexation d’un site ? Qu’entend réellement Google quand on parle de contenu dupliqué ? A l’aide des informations de ces dernières années, des définitions fournies par Google ainsi que des outils et des techniques, cet article vous permettra d’y voir plus clair sur le contenu dupliqué.
Qu’est ce que le contenu dupliqué (duplicate content) ?
La définition officielle de Google du contenu dupliqué, ou contenu « en double » sur un site web, est la suivante :
« Par contenu en double, on entend généralement des blocs de contenu importants, appartenant à un même domaine ou répartis sur plusieurs domaines, qui sont identiques ou sensiblement similaires »
Cette définition apportée sur le support de Google Search Console a de quoi alimenter toutes les théories et interpretations tant il se trouve qu’elle est large.
Quels sont les cas de contenus dupliqués et comment le différencier du plagiat ?
Du contenu produit sur un site est considéré comme contenu dupliqué, ou « duplicate content », lorsqu’il est présent identiquement en plusieurs fois sur Internet. Cela ne concerne pas quelques mots ou phrases prises sur des sites divers, mais lorsque le contenu en question copie une part importante d’un autre, ou du même site. La tolérance est placée à environ 40% de similitudes. Il faut cependant les réduire au maximum, et bien évidemment éviter les copies de contenus externes de blocs entiers de textes.
Voici quelques exemples donnés par Google, considérés comme contenus dupliqués :
- Contenu copié collé d’un site à l’autre. Ex : des citations
- Plusieurs Urls pointant vers une même page, Google les traitant comme deux pages distinctes.
- Balises title ou meta description se répétant sur le site.
- Si le site existe en plusieurs versions identique sous http et https, ou avec et/ou sans préfixe www.
Et quelques exemples de contenus pouvant ne pas être perçus comme dupliqué :
- Les articles de site de ventes, présents sur plusieurs urls (fiches produits, e-commerce),
- Les versions imprimables des pages web,
- Les pages mobiles distinctes de leur homologue desktop.
A noter que Google fait une claire distinction entre deux cas de duplicate content, à savoir les contenus non malveillants ( cités ci-dessus) et les contenus dupliqués comme moyen de tromper l’algorithme de Google et essayer de remonter dans les résultats de recherches. Ces pratiques tiennent plus du plagiat que de contenu dupliqué à proprement parler et sont illégales.
Pour remédier à cela, Google essaiera de trouver la source d’origine du contenu et privilégiera son positionnement par rapport aux pages incluant du contenu dupliqué.
Protocole, migration http/https et duplicate content
Un échec lors de la migration http à https peut aboutir à une double indexation du site, soit une indexation par protocoles. Ce cas de figure entraîne du contenu dupliqué comme dans l’exemple suivant :
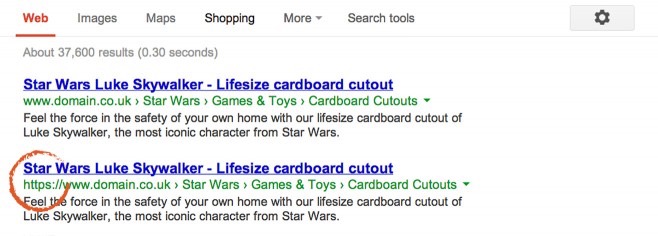
Pour bien réussir votre transition de http vers https en évitant le contenu dupliqué, vous pouvez suivre notre webinar de suivi de migration http/https avec Myposeo (vidéo).
Publier son contenu également depuis les réseaux sociaux ou plateformes de contenus est-il considéré comme contenu dupliqué ?
Nous pouvons relever un autre cas de contenu en double, qui n’est pas cité directement dans les directives de Google. En effet, les webmasters se demandent si re-publier sur Medium ou LinkedIn Pulse un contenu déjà publié précédemment sur son site, est considéré comme duplicate content ou non ? Nous avons d’ores et déjà répondu à cette question dans un précédent article du blog Myposeo. Cela n’est à priori pas le cas dès lors que la source du contenu est bien identifiée.
Comment le contenu dupliqué affecte mon référencement ?
Le mythe du contenu dupliqué
Les experts SEO ont longtemps pensé que le contenu dupliqué était une cause de pénalité voir de désindexation de son site par Google. C’est suite à la mise à jour Google Panda, en février 2011, destinée à lutter contre les fermes de contenus et les sites de basse qualité, que les rumeurs de pénalités se sont ravivées. En effet, la nouvelle mise à jour pénalisait de nombreux sites et a suscité une détresse auprès des webmasters autour du monde, ne faisant plus la différence entres contenus dupliqués et plagiés.
De nombreuses questions ont été posées sur des forums de discussions, s’interrogant sur des potentiels blâmes liés aux contenus dupliqués pour leur site. L’exemple suivant provient des forums de Moz :
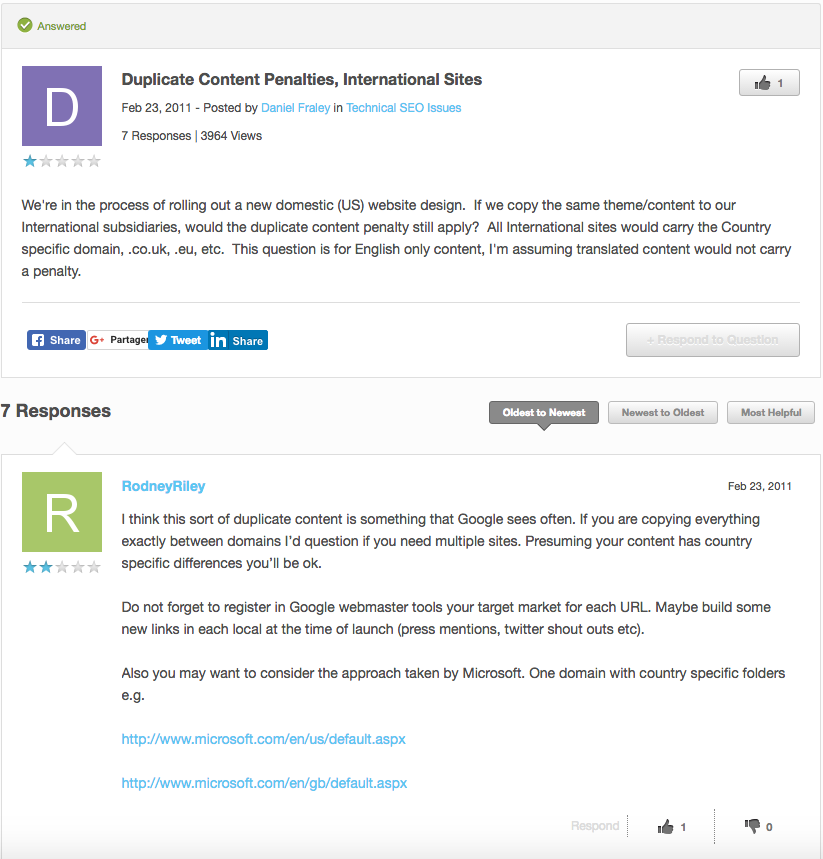
« La question : Nous procédons à une migration vers un site US. Si nous copions le même contenu et thèmes que notre filiale internationale, la pénalité de contenu dupliqué s’applique-t-elle tout de même ? […] »
« La réponse : Je pense que c’est une sorte de contenu dupliqué que Google voit souvent. Si tu copies tout d’un site à l’autre, je me demande si tu as besoin de plusieurs sites. […] »
Quelques années après, la question d’une pénalité due aux contenus dupliqués continue d’occuper les esprits. Le commentaire suivant a été trouvé sur un article de Kissmetrics traitant du mythe autour du contenu dupliqué :

« Merci pour le commentaire Rick. Le but de l’article était en partie, de parler du mythe du contenu dupliqué mais aussi d’avoir des retours d’expériences. Si vous voyez un exemple de pénalité, faîtes-moi savoir! »
La confusion a même entraîné le site Kern Média à inclure les contenus dupliqués dans son guide pour éviter les pénalités de la mise à jour Google Panda.

« De nombreux sites ont été pénalisés par la mise à jour Google Panda pour avoir produit des contenus dupliqués, intentionnellement ou non. Peu importe le système de gestion de contenu (WordPress, Magento, Drupal etc.) tous les sites y sont vulnérables si les précautions nécessaires ne sont pas prises. Ce guide SEO du contenu dupliqué a été crée pour chercher, trouver et corriger les contenus dupliqués. Le but est de protéger son site des prochaines mises à jour Google Panda. »
Qu’en est-il réellement? Que savons nous des sanctions que peut entraîner le contenu dupliqué, à travers les informations officielles fournies par Google?
La réalité du contenu dupliqué
Depuis septembre 2008, Susan Mowska a essayée de taire les rumeurs quant au contenu dupliqué. En effet, l’algorithme détecte bel et bien le contenu dupliqué en ralentissant l’indexation des sites qui en utilise, mais ne donnera lieu en aucun cas à une sanction ou une désindexation.
En juin 2016 Andrey Lipattsev, Search Quality Senior Strategist chez Google Irlande est allé plus loin en précisant, au cours d’une session Q&A, que l’algorithme ne pénalise pas les sites au contenu dupliqué, tant qu’une interprétation ou un commentaire pertinent est ajouté. Il précise également que la priorité devrait être la différenciation de l’expérience, par rapport à la concurrence et non pas sur le contenu dupliqué.
Voici la session Google Q&A en question :
Nous savons maintenant que le duplicate content n’est pas aussi grave que l’on pensait, en utiliser peut tout de même entrainer de la perte de ranking, ou un ralentissement de l’indexation du site par Google. L’algorithme saura faire le tri entre le contenu unique et dupliqué, et voir si de la valeur a été ajoutée à ce contenu.
Comment détecter et remédier aux contenus dupliqués ?
Il est légitime de penser qu’il suffit d’empêcher Google de crawler et indexer les pages intégrant du contenu dupliqué avec un robot.txt. Pourtant, Google déconseille cette pratique dans ce cas de figure et recommande les techniques suivantes :
Etre prudent avec son contenu, limiter le contenu similaire
C’est la technique qui parait la plus évidente, mais elle reste bonne à rappeler. Il est donc important de bannir le copier-coller d’autres sites, et veiller à toujours produire un contenu unique ou au moins propre à notre site. Google conseille d’écrire, non pas pour le moteur de recherche, mais pour les visiteurs du site. Cette simple consigne épargnera bien des cas de contenus en double, et doit être vérifiée avant même de s’atteler à la partie plus technique de l’optimisation du référencement.
Faire des redirections 301
Lorsque Google indexe des liens vers des pages de contenu dupliqué d’un même site, il est conseillé de faire des redirections 301 côté serveur. Ces redirections devront se faire de la page dupliquée à la page principale et de cette manière, le crawler saura quelle page devra être la mieux indexée.
Canonicalisations des urls
Utiliser des URL canoniques permet d’indiquer au moteur de recherche une page de référence à indexer dans un cas où plusieurs pages du même site ont un contenu dupliqué. De cette manière, Google ne choisira pas de lui-même la page à indexer et ne considèrera pas les pages similaires comme contenu dupliqué.
Pour utiliser une URL canonique, celle-ci doit être placée dans la partie <head> de la page de référence et des pages au contenu similaire :
<link rel= « canonical » href= « http://site.fr/url-de-references.html »/>
Préciser au crawler de ne pas indexer une page du site en particulier.
< meta name = « robot » content = « Noindex, Follow » >
Avec cette balise, nous précisons à Google que nous ne souhaitons pas que cette page soit indexée, mais tout de même explorée par Google. Il est important de laisser le robot crawler (lire) les pages de contenu dupliqué, car le dissimuler peut entraîner des sanctions en terme de positionnement.
Ce bout de code doit être ajouté dans la section <head> de la page concernée. Cette solution est idéale pour les différentes pages d’une pagination.
Bien régler son site sur la Search Console
Avec l’aide de la Search Console, vous pouvez indiquer votre domaine favori dans les réglages à savoir avec ou sans www. En choisissant lequel Google doit indexer, il sera plus facile d’éviter le contenu dupliqué entraîné par la double indexation du site avec www.exemple.com et exemple.com. Le réglage doit se faire de la manière suivante :
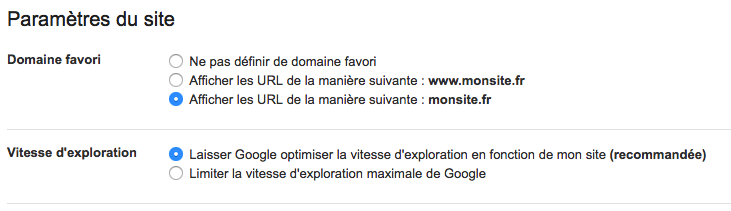
Il est également possible de guider le bot de Google par l’interprétation des paramètres d’URL. Si un contenu se répète d’une page à l’autre tel que des mentions légales, il suffira de faire un lien vers une page plus détaillée et le préciser dans la Search Console. Un guide d’utilisation du réglage de paramètres d’URL est disponible ici.
Des outils pour vérifier, trouver et prévenir les contenus dupliqués
Kill Duplicate
Kill Duplicate est un outil permettant de détecter les pages plagiant votre site et contacter les propriétaires des sites voleurs. Si l’échange n’aboutit pas, une option permet de contacter l’hébergeur qui pourra prendre des mesures contre ce plagiat.
La MOZ bar
La MOZ bar est un plugin pour moteur de recherche qui permet d’identifier les balises title, meta description mais aussi les urls canoniques utilisées sur les pages que vous visitez.
Sources :
Support Google Webmasters, https://www.hobo-web.co.uk/duplicate-content-problems/
Https://support.google.com/webmasters/answer/6080548?visit_id=1-636385707940773723-2205780584&rd=2
https://support.google.com/webmasters/answer/93633

Carol-Ann
Responsable marketing @myposeo, community manager et rédactrice.
- More Posts (664)